













簡介
Apache Cassandra 將資料儲存在表格中,每個表格包含列和欄。CQL (Cassandra 查詢語言) 用於查詢儲存在表格中的資料。Apache Cassandra 資料模型以查詢為基礎並針對查詢進行最佳化。Cassandra 不支援關係資料庫所使用的關係資料建模。
什麼是資料建模?
資料建模是識別實體及其關係的過程。在關係資料庫中,資料會置於正規化的表格中,並使用外來鍵來參照其他表格中的相關資料。應用程式所做的查詢是由表格結構所驅動,而相關資料則會以表格聯結的方式進行查詢。
在 Cassandra 中,資料建模是受查詢驅動的。資料存取模式和應用程式查詢會決定資料的結構和組織,然後用於設計資料庫表格。
資料會根據特定查詢進行建模。查詢最適合存取單一表格,這表示查詢中所涉及的所有實體都必須在同一個表格中,才能讓資料存取 (讀取) 非常快速。資料會建模成最適合查詢或一組查詢。一個表格可以包含一個或多個最適合查詢的實體。由於實體通常彼此之間有關係,而且查詢可能涉及彼此之間有關係的實體,因此單一實體可能會包含在多個表格中。
受查詢驅動的建模
與關係資料庫模型不同,關係資料庫模型中的查詢會使用表格聯結從多個表格取得資料,Cassandra 中不支援聯結,因此所有必要的欄位 (欄) 都必須分組在單一表格中。由於每個查詢都由表格支援,因此資料會在多個表格中重複,這個過程稱為非正規化。資料重複和高寫入量會用於達成高讀取效能。
目標
主鍵和分割鍵的選擇對於在叢集中均勻分配資料非常重要。將查詢所讀取的分割數保持在最低限度也很重要,因為不同的分割可能位於不同的節點上,而協調器需要向每個節點傳送請求,這會增加請求的負擔和延遲。即使查詢中所涉及的不同分割位於同一個節點上,較少的分割也會讓查詢更有效率。
分割
Apache Cassandra 是分散式資料庫,會將資料儲存在節點叢集中。分割鍵用於在節點之間分割資料。Cassandra 使用一致性雜湊的變體來在儲存節點上分割資料,以進行資料分配。雜湊是一種用於對應資料的技術,其中雜湊函數會根據給定的鍵產生雜湊值 (或簡稱雜湊),並儲存在雜湊表中。分割鍵會從主鍵的第一個欄位產生。使用分割鍵將資料分割到雜湊表中,可提供快速查詢。查詢所使用的分割越少,查詢的回應時間就越快。
作為分割的範例,請考慮表 t,其中 id 是主鍵中的唯一欄位。
CREATE TABLE t ( id int, k int, v text, PRIMARY KEY (id) );
分割鍵從主鍵 id 產生,用於在叢集中的節點間分配資料。
考慮表 t 的變形,其中兩個欄位構成主鍵,形成複合或組成主鍵。
CREATE TABLE t ( id int, c text, k int, v text, PRIMARY KEY (id,c) );
對於具有複合主鍵的表 t,第一個欄位 id 用於產生分割鍵,第二個欄位 c 是用於在分割內排序的叢集鍵。使用叢集鍵對資料排序,可以更有效率地擷取相鄰的資料。
一般而言,主鍵的第一個欄位或組成會進行雜湊以產生分割鍵,其餘的欄位或組成是叢集鍵,用於在分割內排序資料。分割資料可以提升讀取和寫入的效率。其他非主鍵欄位可以個別建立索引,以進一步提升查詢效能。
如果分割鍵被分組為主鍵的第一個組成,則可以從多個欄位產生分割鍵。作為表 t 的另一個變形,請考慮一個表,其主鍵的第一個組成是由使用括號分組的兩個欄位組成。
CREATE TABLE t ( id1 int, id2 int, c1 text, c2 text k int, v text, PRIMARY KEY ((id1,id2),c1,c2) );
對於前述的表 t,構成欄位 id1 和 id2 的主鍵的第一個組成用於產生分割鍵,其餘的欄位 c1 和 c2 是用於在分割內排序的叢集鍵。
與關聯資料模型的比較
關聯式資料庫將資料儲存在與其他資料表使用外來鍵建立關聯的資料表中。關聯式資料庫對資料建模的方法以資料表為中心。查詢必須使用資料表聯結,才能從具有關聯的資料表中取得資料。Apache Cassandra 沒有外來鍵或關聯性完整性的概念。Apache Cassandra 的資料模型是圍繞設計有效率的查詢,也就是不涉及多個資料表的查詢。關聯式資料庫正規化資料以避免重複。Apache Cassandra 則相反,透過在多個資料表中重複資料,對資料進行非正規化,以建立以查詢為中心的資料模型。如果 Cassandra 資料模型無法完全整合不同實體之間的關係複雜性,以進行特定查詢,則可以在應用程式程式碼中使用用戶端聯結。
資料建模範例
例如,magazine 資料集包含雜誌資料,其屬性包括雜誌 ID、雜誌名稱、出版頻率、出版日期和發行商。雜誌資料的基本查詢 (Q1) 是列出所有雜誌名稱,包括其出版頻率。由於 Q1 不需要所有資料屬性,因此資料模型只會包含 id (用於分割鍵)、雜誌名稱和出版頻率,如圖 1 所示。
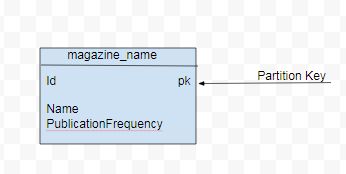
另一個查詢 (Q2) 是按發行商列出所有雜誌名稱。對於 Q2,資料模型會包含一個額外的屬性 publisher 作為分割鍵。id 會成為分割內排序的叢集鍵。Q2 的資料模型如圖 2 所示。
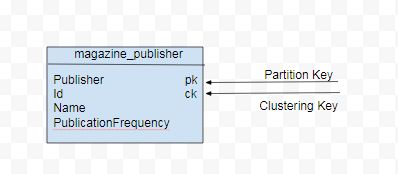
設計架構
建立概念資料模型後,可以為查詢設計架構。對於 Q1,可以使用下列架構。
CREATE TABLE magazine_name (id int PRIMARY KEY, name text, publicationFrequency text)對於 Q2,架構定義會包含一個用於排序的叢集鍵。
CREATE TABLE magazine_publisher (publisher text,id int,name text, publicationFrequency text,
PRIMARY KEY (publisher, id)) WITH CLUSTERING ORDER BY (id DESC)資料模型分析
資料模型是一個概念模型,必須根據儲存、容量、備援和一致性進行分析和最佳化。資料模型可能需要根據分析結果進行修改。資料模型分析中使用的考量或限制包括
-
分割大小
-
資料備援
-
磁碟空間
-
輕量級交易 (LWT)
分割大小的兩個衡量標準是分割中的值數和磁碟上的分割大小。儘管這些衡量標準的要求可能因應用程式而異,但一般準則是不讓每個分割的值超過 100,000,且每個分割的磁碟空間不超過 100MB。
資料模型設計中預期會有資料備援,例如表格中的重複資料和多個分割複本,但仍應將其視為參數,並將其保持在最低限度。LWT 交易 (比較和設定、條件更新) 可能會影響效能,因此應將使用 LWT 的查詢保持在最低限度。