













存储附加索引 (SAI) 概念
存储附加索引 (SAI) 是 Cassandra 数据库中高度可扩展的全局分布式索引。
与 Apache Cassandra 的现有索引相比,SAI 的主要优势是
-
为 AI 应用程序启用向量搜索
-
在同一张表上跨多个索引共享公共索引数据
-
缓解写入时可扩展性问题
-
显著减少磁盘使用量
-
极佳的数字范围性能
-
索引的零拷贝流式传输
事实上,SAI 为 Apache Cassandra 提供了最丰富的索引功能。SAI 将列级索引添加到任何 CQL 表列,几乎适用于任何 CQL 数据类型。
SAI 启用基于以下条件进行筛选的查询
-
向量嵌入
-
数字和文本类型的 AND/OR 逻辑
-
数字和文本类型的 IN 逻辑(使用值数组)
-
数字范围
-
非可变长度数字类型
-
文本类型相等性
-
CONTAINs 逻辑(适用于集合)
-
标记化数据
-
行感知查询路径
-
区分大小写(可选)
-
Unicode 规范化(可选)
优势
根据数据库表中的任何列定义一个或多个 SAI 索引,随后便可以运行指定索引列的高性能查询。与关系数据库和复杂的索引方案相比,SAI 通过加速开发应用程序的路径,让您更高效。
SAI 与 Cassandra 的存储引擎深度集成。SAI 功能在写入时对内存中的 memtable 和磁盘上的 SSTable 进行索引,并在读取时解决这些索引之间的差异。因此,SAI 的设计在核心数据库之上几乎没有操作复杂性。从快照创建到模式管理再到数据过期,SAI 与核心数据库已提供的功能和机制紧密集成。
SAI 还完全兼容零拷贝流式传输 (ZCS)。因此,当您引导或解除群集中的节点时,索引将通过 SSTable 完整流式传输,而不会在接收节点端序列化或重建。
从本质上讲,SAI 是一个过滤引擎,它简化了数据建模和客户端应用程序,而这些应用程序原本在很大程度上依赖于维护多个特定于查询的表。
效能
SAI 的效能優於適用於 Apache Cassandra 的任何其他索引方法。
SAI 提供的功能比次要索引 (2i) 多,使用的磁碟空間卻不到後者的零頭,並降低磁碟、基礎架構和作業的總擁有成本 (TCO)。在讀取路徑效能方面,SAI 在處理量和延遲方面至少與其他索引方法一樣好。
SAI 寫入路徑和讀取路徑
SAI 與基礎資料庫的儲存引擎深度整合。SAI 沒有抽象地索引表格。相反地,SAI 會在寫入時索引記憶表和排序字串表 (SSTable),並在讀取時解決這些索引之間的差異。每個記憶表都是特定於特定資料庫表格的記憶體中資料結構。記憶表類似於寫回快取。每個 SSTable 都是資料庫定期將記憶表寫入的不可變資料檔案。SSTable 會依序儲存在磁碟上,並針對每個資料庫表格進行維護。
本主題討論 SAI 讀取和寫入路徑的詳細資訊,並探討 SAI 索引生命週期。
SAI 寫入路徑
SAI 索引可以在寫入任何資料到 CQL 表格之前或之後建立。作為複習,寫入 CQL 表格的資料會先寫入記憶表,然後在資料從記憶表清除後寫入 SSTable。在建立 SAI 索引後,SAI 會收到針對目前記憶表的所有變更通知。如同任何其他資料,SAI 會更新插入和更新的索引,而 Apache Cassandra 會以完全相同的方式處理這些索引。SAI 也支援分割刪除、範圍墓碑和列移除。如果在查詢中執行刪除作業,SAI 會在後過濾步驟中處理索引變更。因此,SAI 在索引頻繁刪除的欄時不會造成任何特殊損失。
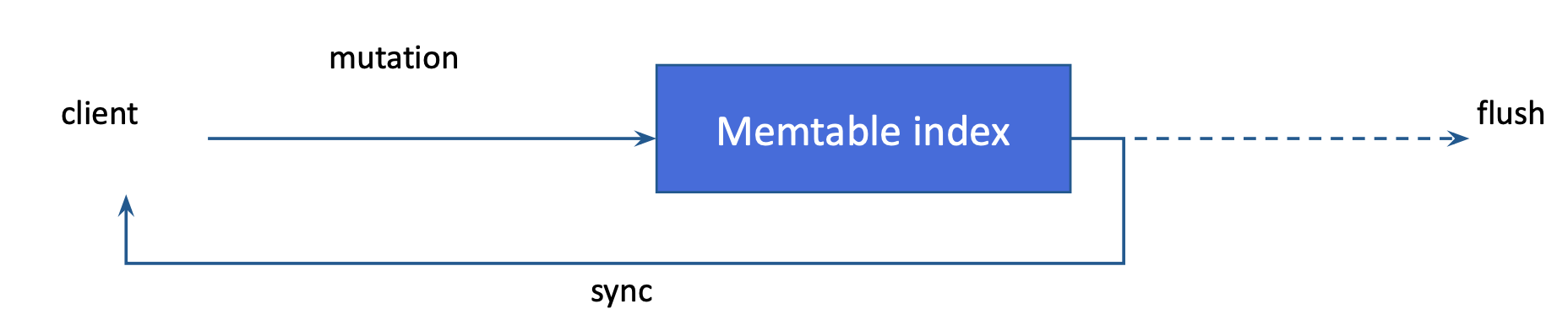
如果插入或更新包含索引欄的有效內容,該內容會新增到記憶表索引,且更新列的主鍵會與索引值關聯。SAI 會計算新條目的增量堆積使用量估計值。此估計值會計入基礎記憶表的堆積使用量。此功能也表示,隨著表格中索引的欄位增加,記憶表清除率會增加,且清除的 SSTable 大小會減少。所有即時記憶表索引的總寫入次數和估計堆積使用量會顯示為指標。請參閱 SAI 指標。
Memtable flush
當達到 flush 閾值時,SAI 會將 Memtable 索引內容直接 flush 到磁碟,而不是建立額外的記憶體中表示。這是因為 Memtable 索引會先依據詞彙/值排序,然後再依據主鍵排序。當 flush 發生時,SAI 會在 SSTable 寫入時,為每個索引欄位寫入新的 SSTable 索引。
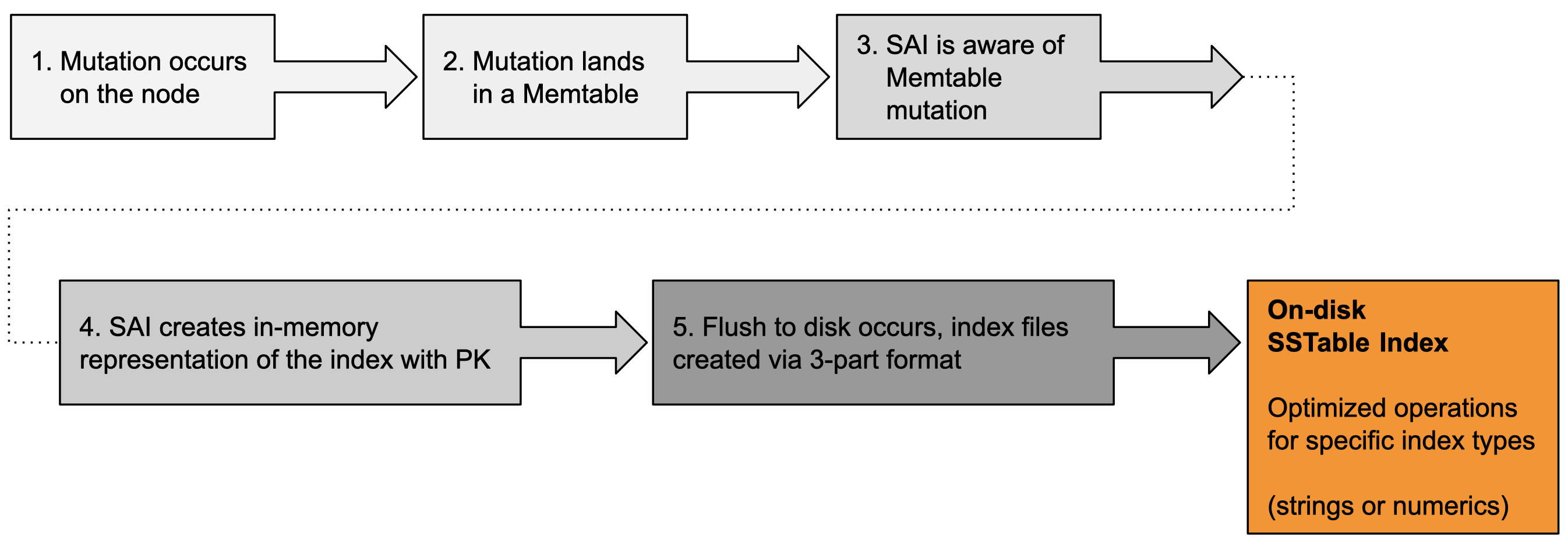
flush 作業是一個兩階段的程序。在第一階段,列會寫入新的 SSTable。對於每一列,會產生一個列 ID,並建立三個索引元件。這些元件是
-
列 ID 到其對應權杖值的磁碟對應 — SAI 支援 Murmur3Partitioner
-
SSTable 分割偏移
-
主鍵到其列 ID 的暫時對應,用於後續階段
第一個和第二個元件檔案的內容是壓縮陣列,其序數對應於列 ID。
在第二階段,當所有列都寫入新的 SSTable,且共用的 SSTable 層級索引元件已完成後,SAI 會開始針對每個索引欄位進行索引工作。特別是在第二階段,SAI 會反覆運算 Memtable 索引,以產生詞彙及其權杖排序的列 ID。這個反覆運算器會使用在第一階段建立的暫時對應結構,將主鍵轉換為列 ID。然後會將詞彙反覆運算器(含張貼)傳遞給不同的寫入元件,視每個索引元素是針對字串或數字欄位而定。
在字串情況下,SAI 索引寫入器會反覆運算每個詞彙,先將其張貼寫入磁碟,然後將這些張貼的偏移記錄在張貼檔案中,作為磁碟上、位元組順序 trie 中新條目的有效負載(針對詞彙本身)。在數字情況下,SAI 會將數字索引的寫入分為兩個步驟
這些術語傳遞給平衡的 KD 樹寫入器,它將 KD 樹寫入磁碟。當樹的葉子區塊寫入時,它們的張貼會暫時記錄在記憶體中。然後,這些暫時張貼用於在葉子以及索引節點的各種層級上建立磁碟上的張貼。
當欄位索引快取完成時,會標記一個特殊的空標記檔案以指示成功。此程序用於啟動和增量重建作業,以區分下列情況:
-
欄位的 SSTable 索引檔案遺失。
-
沒有可索引的資料,例如當 SSTable 僅包含墓碑時。(墓碑是列中表示欄位已刪除的標記。在壓縮期間,標記的欄位會被刪除。)
然後,SAI 會增加欄位快取索引快取的計數器,並將每秒快取的儲存格數目新增到直方圖中。
當觸發壓縮時
請回想 Apache Cassandra 使用壓縮來合併 SSTable。壓縮會收集每個唯一列的所有版本,並使用各個 SSTable 中列的最即時版本(依時間戳記)組成一個完整的列。合併程序的效能很好,因為列依據每個 SSTable 中的分區金鑰排序,而且合併程序不會使用隨機 I/O。每個列的新版本會寫入新的 SSTable。舊版本以及任何準備刪除的列會留在舊的 SSTable 中,並在完成所有待處理的讀取時刪除。
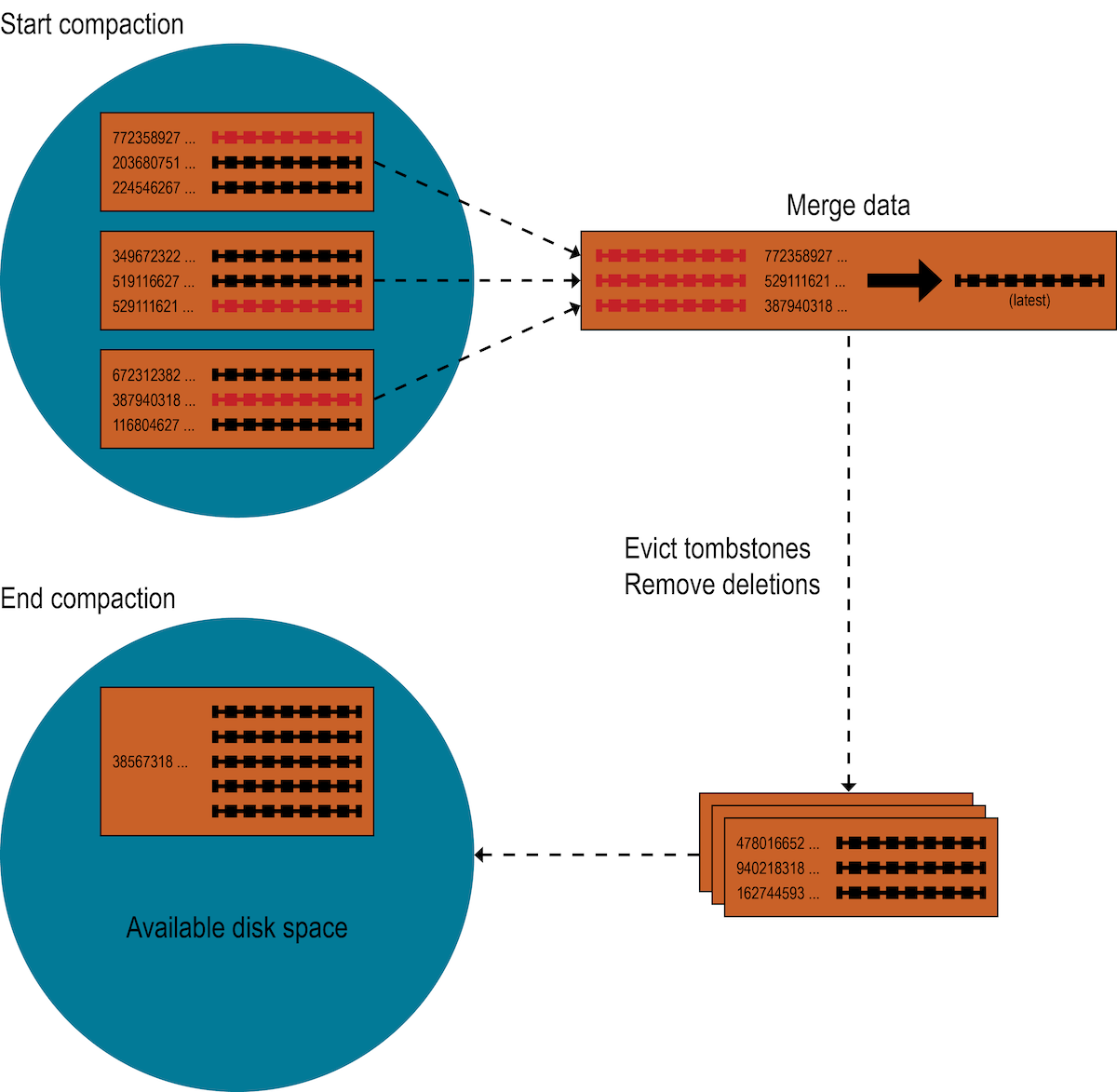
對於 SAI,當觸發壓縮時,每個索引群組會建立一個 SSTable 快取觀察器,以協調從其各自的 SSTable 寫入器實例中編寫所有附加的欄位索引的程序。與快取快取(已排序索引術語)不同,在壓縮期間反覆處理合併資料時,SAI 會快取索引值及其列 ID,這些值和 ID 會依據標記順序新增。
為了避免耗盡可用堆積資源等問題,SAI 會使用累積區段快取,它會使用專有計算同步快取到磁碟。然後,每個區段會記錄區段列 ID 偏移量,並僅儲存區段列 ID(SSTable 列 ID 減去區段列 ID 偏移量)。SAI 會同步將區段快取到同一個檔案,以避免重寫所有區段的成本,並降低分區限制查詢和分頁範圍查詢的成本,因為它會減少搜尋空間。
從每欄索引張貼到 SSTable 偏移量,再到 SSTable 分區的磁碟配置
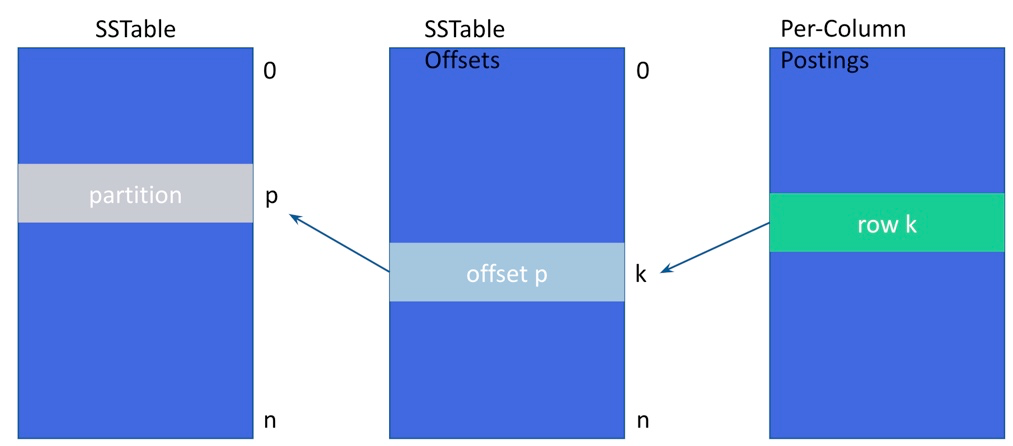
實際的區段清除程序與 Memtable 清除非常類似。不過,在將緩衝詞彙連同其張貼寫入各自特定類型的磁碟結構之前,會先將其排序。在給定索引完成壓縮後,會標記一個特殊的空標記檔案以表示成功,並將區段數目記錄在 SAI 指標中。請參閱全域索引指標。
當整個壓縮任務完成時,SAI 會收到 SSTable 清單變更通知,其中包含在交易期間新增和移除的 SSTable。SSTable Context Manager 和 Index View Manager 負責以原子方式將舊的 SSTable 索引替換為新的索引。此時,新的 SSTable 索引可供查詢使用。
SAI 讀取路徑
此部分說明 SAI 協調器如何處理索引查詢,以及複製品如何執行查詢。與傳統的次要索引不同(在傳統的次要索引中,每個查詢最多只會使用一個欄位索引),SAI 實作了一個查詢計畫,讓單一查詢可以使用所有可用的欄位索引。
SAI 讀取作業的整體流程如下
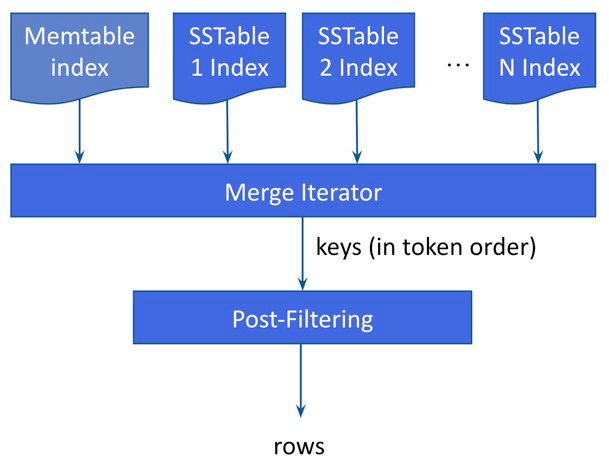
索引選取和協調器處理
當收到查詢時,SAI 協調器執行的第一個動作是找出最具選擇性的索引,以利用一個或多個索引。最具選擇性的索引是會最積極縮小過濾空間和最終結果數目的索引,方法是傳回估計結果列計算中的最低值。如果有多個 SAI 索引(也就是每個 SAI 索引都基於不同的欄位,但查詢涉及多個欄位),則先選取哪個 SAI 索引並無所謂。
一旦選取到最佳的讀取操作索引,索引便會嵌入讀取指令中,並進入分布式範圍讀取裝置。分布式範圍讀取會依據令牌順序,在 Apache Cassandra 集群中查詢一或多輪。SAI 協調器會根據本機資料和查詢限制,估計並行處理係數,也就是每個範圍的行數,以決定要連繫的範圍數量。對於每一輪,並行處理係數會決定要並行查詢多少個複本。
在第一輪開始之前,SAI 會透過專有計算估計初始並行處理係數,此處顯示為步驟 1。
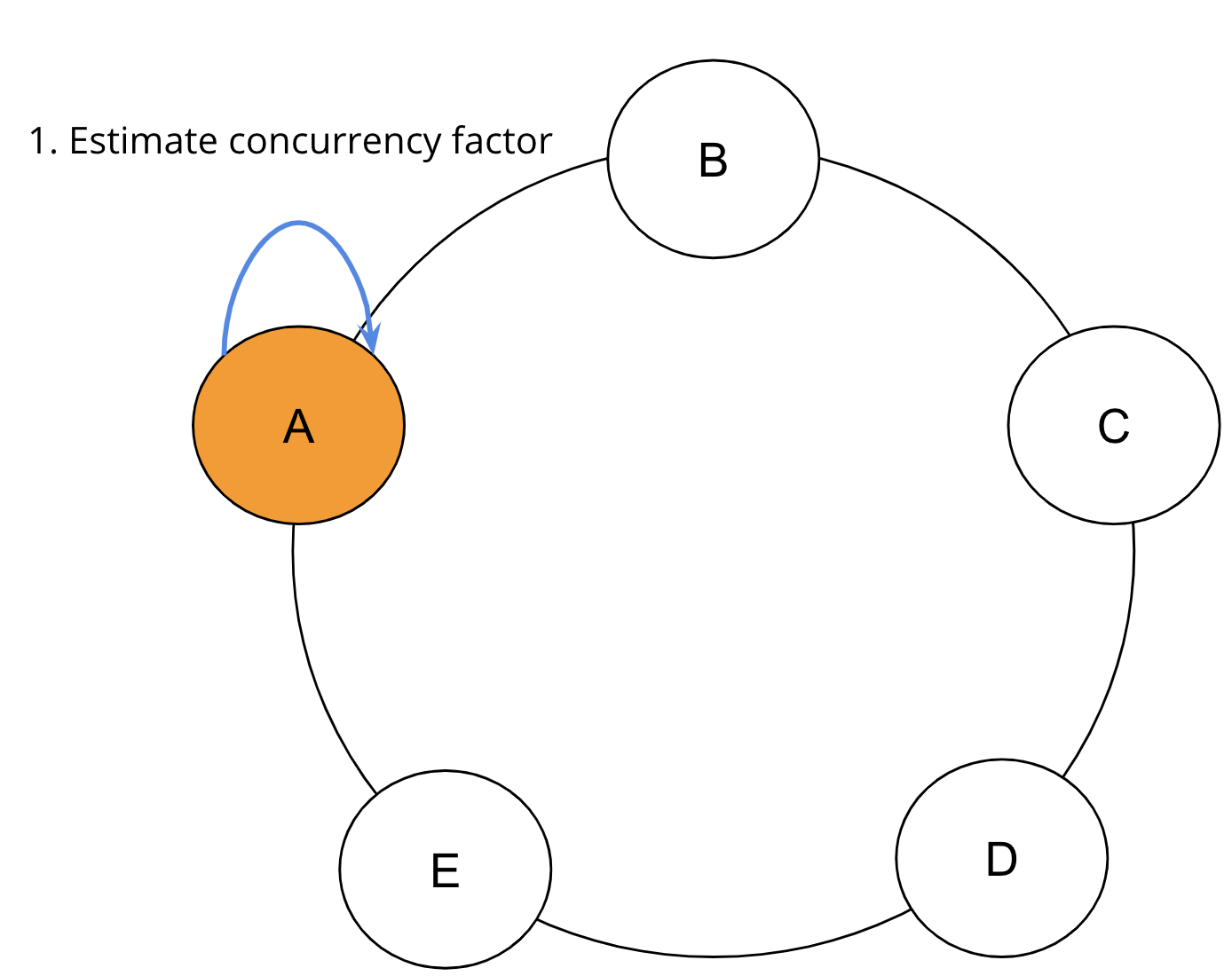
一旦建立初始並行處理係數,範圍讀取便會開始。
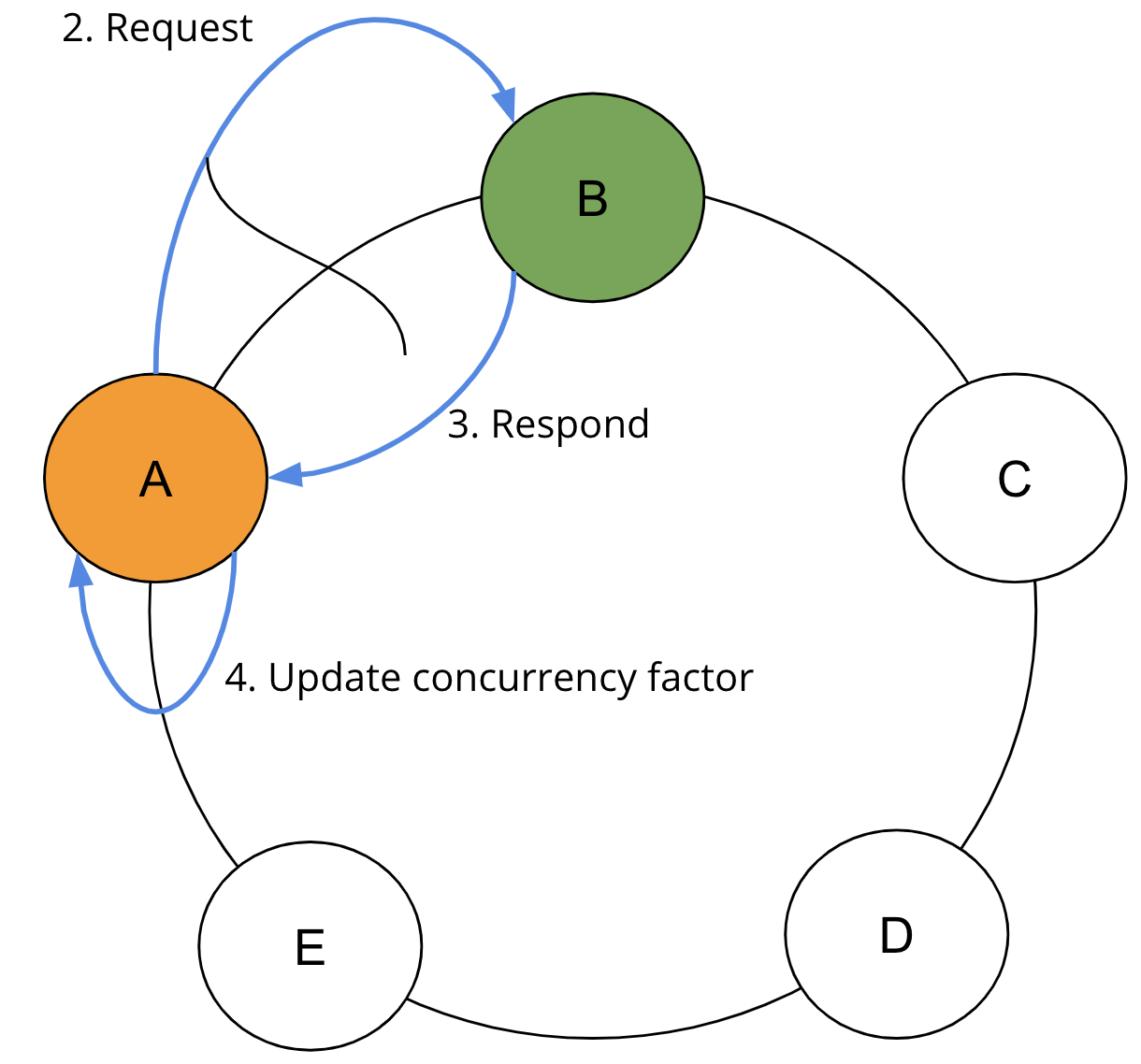
在步驟 2 中,SAI 協調器會根據並行處理係數,並行將要求傳送至所需的範圍。在步驟 3 中,SAI 協調器會等待來自所要求複本的回應。而在步驟 4 中,SAI 協調器會收集結果,並根據傳回的行和查詢限制重新計算並行處理係數。
在每一輪完成時,如果尚未達到限制,便會調整並行處理係數,以考量已讀取結果的形狀。如果第一輪未傳回任何結果,便會立即將並行處理係數增加至剩餘令牌範圍的最小計算值和並行處理係數的最大計算值。如果傳回結果,便會更新並行處理係數。SAI 會重複步驟 2、3 和 4,直到滿足查詢限制。
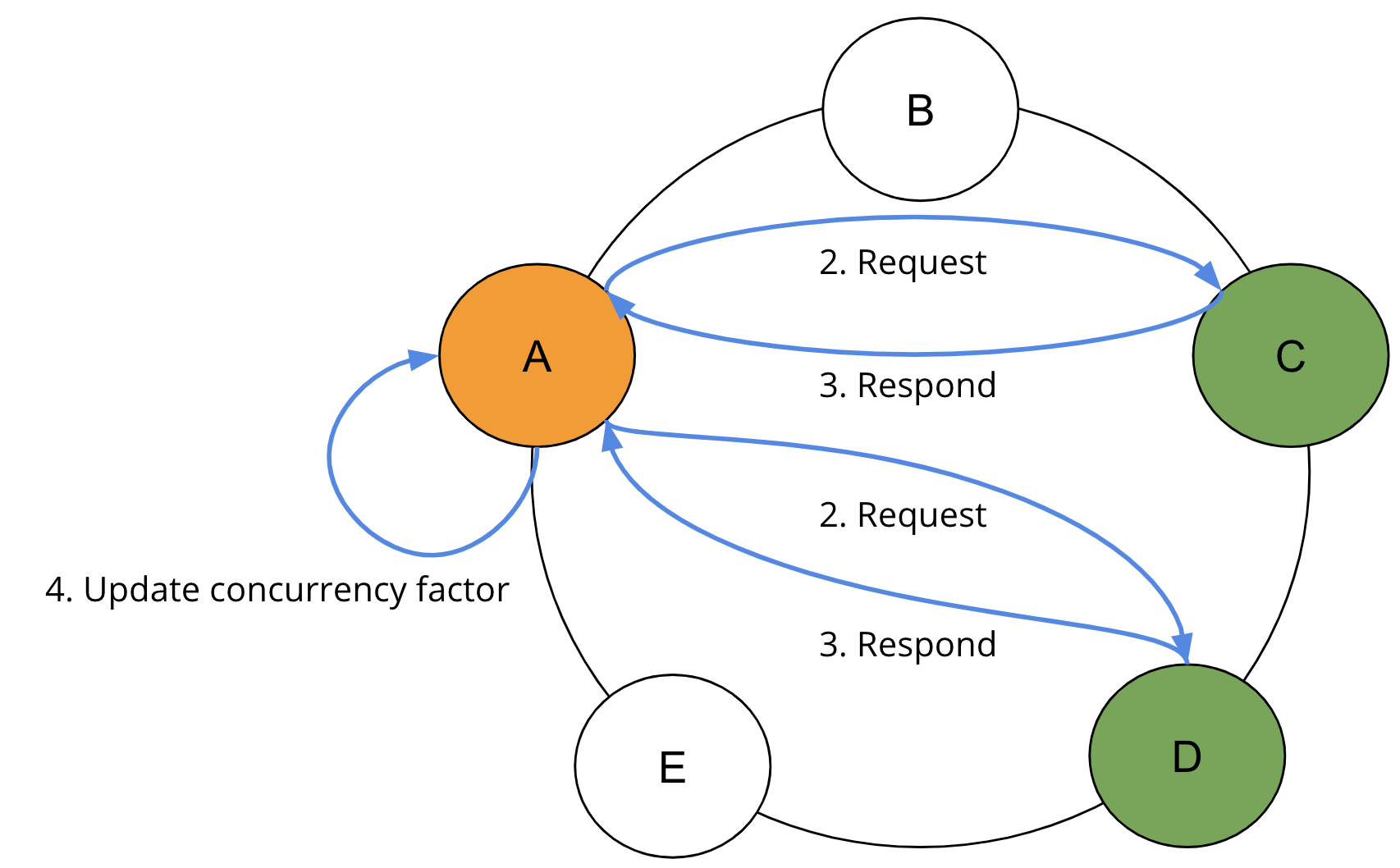
為避免查詢具有失敗索引的複本,每個節點會透過八卦將其自己的本機索引狀態傳播至對等節點。在協調器中,讀取要求會篩選包含要求中所使用之不可查詢索引的複本。在大部分情況下,第二輪複本查詢應會傳回所有必要的結果。如果結果在複本中的分佈極度不平衡,則可能需要進一步的輪次。
深入探討:複本查詢規劃和檢視取得
一旦複本從 SAI 協調器收到令牌範圍讀取要求,便會開始本機索引查詢。SAI 透過查詢計畫實作索引搜尋器介面,讓使用者能夠在單一查詢中存取所有可用的 SAI 欄索引。
查詢計畫會分析透過讀取指令傳遞給它的表達式。SAI 會決定應使用哪些索引來滿足給定欄位上的查詢子句。一旦欄位表達式與索引配對,查詢控制器便會取得每個欄位索引的活動 SSTable 索引檢視。為了避免壓縮移除正在進行查詢所使用的索引檔案,查詢控制器會在讀取任何索引檔案之前,嘗試取得與查詢的令牌範圍相交的索引檔案的 SSTable 參考,並在讀取要求完成時釋放它們。
此時,會建立令牌流程以串流每個欄位索引的比對。這些流程,以及決定如何合併它們的布林邏輯,會包裝在一個操作中,並傳回至查詢計畫元件。
SAI Token Flow 架構的角色
SAI 查詢引擎圍繞著 Token Flow 架構運作,定義 SAI 如何非同步地反覆運算、跳入和合併來自個別 SSTable 索引和整個欄索引的匹配分區串流。SAI 使用令牌來描述 Cassandra 環狀令牌中分區匹配的容器。
反覆運算是最簡單的三個操作。特別是,文章的反覆運算涉及透過區塊快取對列 ID 進行順序磁碟存取,用於查詢環狀令牌和分區金鑰偏移資訊。
令牌跳躍用於在從前一頁面邊界繼續時,或在令牌交集期間找到較大令牌時,跳過不匹配的令牌。
匹配串流和後置篩選範例
考慮一個有個別欄索引的範例(例如 age = 44),產生的串流是所有 Memtable 索引和所有 SSTable 索引的聯集。
-
SAI 透過其個別令牌範圍分區的執行個體,以令牌順序「延遲」反覆運算每個 Memtable 索引(也就是一次一個)。此功能可減少不必要的資料搜尋所產生的額外負擔,這些搜尋會發生在環狀的尾端。
-
磁碟索引:SAI 會傳回所有匹配 SSTable 索引的聯集。在一個 SSTable 索引中,可能會有多個區段,原因是壓縮期間的記憶體限制。與 Memtable 索引類似,SAI 會以令牌排序順序延遲搜尋區段。
當查詢中有許多索引運算式(例如 WHERE age=44 AND state='CA')與 AND 查詢運算子連接時,會交集索引運算式的結果,傳回匹配所有索引運算式的分區金鑰。
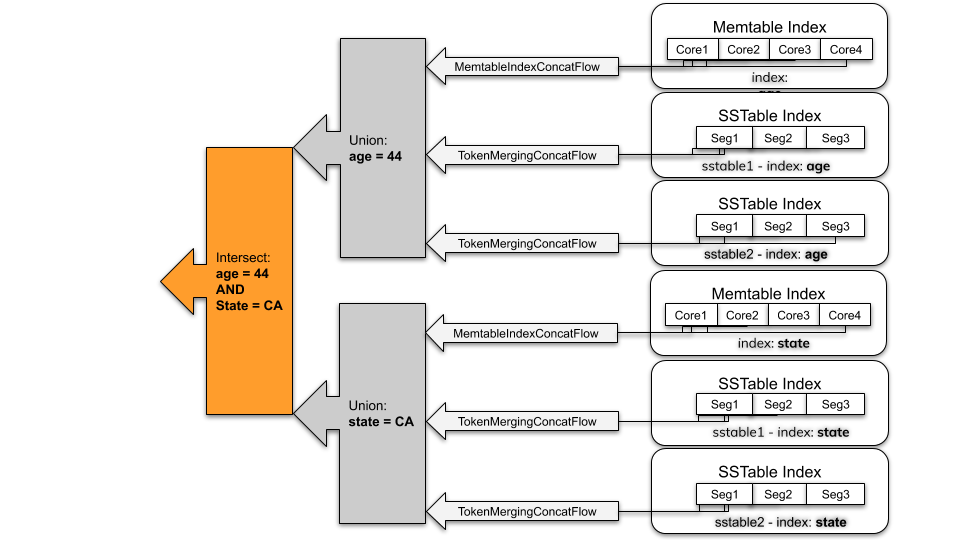
在索引搜尋後,SAI 會公開一個分區金鑰串流。針對每一個分區金鑰,SAI 會執行單一分區讀取操作,傳回給定分區中的列。當列具象化時,SAI 會使用篩選器樹套用另一輪篩選。SAI 會執行此後續篩選步驟,以處理下列事項
-
分區粒度:SAI 會追蹤分區偏移。在寬分區架構的情況下,分區中並非所有列都會匹配索引運算式。
-
墓碑:SAI 沒有索引墓碑。已索引列有可能被新加入的墓碑遮蔽。
-
非索引運算式:操作可能包含沒有索引結構的非索引運算式。
下一步是什麼?
請參閱部落格文章,更好的 Cassandra 索引,帶來更好的資料模型:推出儲存附加索引。