













統一壓縮策略 (UCS)
UnifiedCompactionStrategy (UCS) 建議用於大多數工作負載,無論是讀取密集型、寫入密集型、混合讀寫型或時間序列。無需使用舊版壓縮策略,因為 UCS 可以設定為像任何一種策略一樣運作。
UCS 是一種壓縮策略,結合了其他策略的最佳部分以及新功能。UCS 旨在最大化壓縮速度,這對於高密度節點至關重要,它使用獨特的碎片機制並行壓縮分區資料。而 STCS、LCS 或 TWCS 在變更壓縮策略時需要完整壓縮資料,UCS 可以變更參數來從一個策略切換到另一個策略。事實上,可以同時使用不同的壓縮策略組合,每個層級階層使用不同的參數。最後,UCS 是無狀態的,因此它不依賴任何元資料來做出壓縮決策。
兩個關鍵概念精煉了群組的定義
-
分層和分級壓縮可以概括為等效的,因為兩者都根據 SSTable(或非重疊 SSTable 執行)的大小建立指數增長的層級。因此,當一個層級上存在超過特定數量的 SSTable 時,就會觸發壓縮。
-
大小可以用密度取代,允許在壓縮輸出寫入時在任意點分割 SSTable,同時仍產生分級階層。密度定義為 SSTable 的大小除以其涵蓋的令牌範圍的寬度。
讓我們更詳細地了解第一個概念。
讀取和寫入放大
UCS 可以調整諮詢 SSTable 數量以提供讀取(讀取放大,或 RA)與資料在生命週期中必須重新寫入的次數(寫入放大,或 WA)之間的平衡。單一可設定的縮放參數決定壓縮的行為,從讀取密集模式到寫入密集模式。縮放參數可以隨時變更,壓縮策略也會相應調整。例如,操作員可能會決定
-
當特定表格讀取密集且可以從減少延遲中受益時,降低縮放參數,以犧牲更複雜的寫入為代價來降低讀取放大
-
當識別出壓縮無法跟上寫入表格的數量時,增加縮放參數,以減少寫入放大
任何此類變更只會啟動必要的壓縮,以使階層處於與新組態相容的狀態。任何已經完成的額外工作(例如,從負參數切換到正參數時)是有利的,並且會納入其中。
此外,透過將縮放參數設定為模擬高層級扇出因子,UCS 可以完成與 TWCS 相同的壓縮。
UCS 使用分層和分級壓縮的組合,加上分片,以實現所需的讀取和寫入放大。SSTable 會依據令牌範圍排序,然後分組到各個層級
UCS 會根據 SSTable 密度對數將 SSTable 分組到各個層級,其中扇出因子 \(f\) 作為對數的基底,且每個層級在有 \(t\) 個重疊 SSTable 時會觸發壓縮。
縮放參數 \(w\) 的選擇決定扇出因子 \(f\) 的值。反過來,\(w\) 將模式定義為分級或分層,而 \(t\) 設定為分級壓縮的 \(t=2\),或分層壓縮的 \(t=f\)。最後一個參數,最小 SSTable 大小,是決定 UCS 完整行為的必要條件。
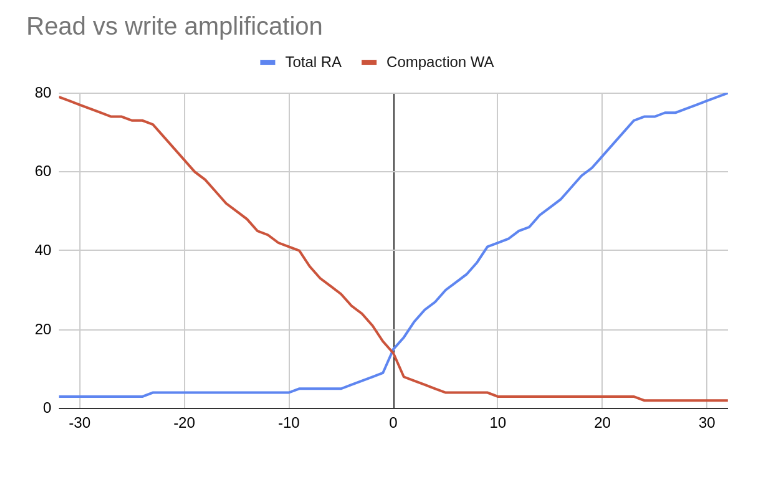
根據上方的 RA 和 WA 圖表,\(w\) 的值可能會有三種壓縮類型
-
平整壓縮,WA 高,RA 低:\(w < 0\),\(f = 2 - w\) 且 \(t=2\) \(L_{f}\) 是用來指定此 \(w\) 值範圍的簡寫(例如,\(w=-8\) 的 L10)。
-
分層壓縮,WA 低,RA 高:\(w > 0\),\(f = 2 + w\) 且 \(t=f\)。\(T_{f}\) 是簡寫(例如,\(w = 2\) 的 T4)。
-
平整和分層壓縮在中心處的行為相同:\(w = 0\) 且 \(f = t = 2\)。簡寫為,\(w = 0\) 的 N。
|
平整壓縮會犧牲寫入而改善讀取,並隨著 \(f\) 的增加而接近已排序陣列,而分層壓縮會犧牲讀取而偏好寫入,並隨著 \(f\) 的增加而接近未排序的記錄。 |
UCS 允許針對每個層級分別定義 \(w\) 的值;因此,層級可以有不同的行為。例如,第 0 層可以採用分層壓縮(類似 STCS),而較高的層級可以採用平整壓縮(類似 LCS),並定義為讀取最佳化的層級。
基於大小的平整化
此策略會在特定分片邊界處分割 SSTable,其數量會隨著 SSTable 的密度而增加。由分割所建立的 SSTable 之間的非重疊,使得同時壓縮成為可能。不過,讓我們暫時忽略密度和分割,並探討如果 SSTable 永不分割,它們將如何分組到層級中。
記憶表會刷新到第 0 層(L0),而記憶表刷新大小 \(s_{f}\) 則計算為在記憶表刷新時寫入的所有 SSTable 的平均大小。此參數 \(s_{f}\) 的目的是形成層級的基礎,所有新刷新的 SSTable 都會出現在此基礎上。使用固定的扇出因子 \(f\) 和 \(s_{f}\),大小為 \(s\) 的 SSTable 的層級 \(L\) 計算如下
SSTable 會根據其大小分配到層級
| 層級 | 最小 SSTable 大小 | 最大 SSTable 大小 |
|---|---|---|
0 |
0 |
\(s_{f} \cdot f\) |
1 |
\(s_{f} \cdot f\) |
\(s_{f} \cdot f^2\) |
2 |
\(s_{f} \cdot f^2\) |
\(s_{f} \cdot f^3\) |
3 |
\(s_{f} \cdot f^3\) |
\(s_{f} \cdot f^4\) |
… |
… |
… |
n |
\(s_{f} \cdot f^n\) |
\(s_{f} \cdot f^{n+1}\) |
一旦 SSTable 開始在層級中累積,當層級中的 SSTable 數量超過前面討論的閾值 \(t\) 時,就會觸發壓縮
-
\(t = 2\),分層壓縮
-
SSTable 會提升到大小為 \(\ge s_{f} \cdot f^n\) 的層級 \(n\)。
-
當第二個 SSTable 提升到該層級(大小也為 \(\ge s_{f} \cdot f^n\))時,它們會壓縮並在同一個層級中形成一個大小約為 \(\sim 2s_{f} \cdot f^n\) 的新 SSTable,其中 \(f > 2\)。
-
在至少重複 \(f-2\) 次之後(即總共有 \(f\) 個 SSTable 進入該層級),壓縮結果會成長到 \(\ge s_{f} \cdot f^{n+1}\) 並進入下一個層級。
-
-
\(t = f\),分層壓縮
-
在 \(f\) 個 SSTable 進入層級 \(n\) 之後,每個大小都為 \(\ge s{f} \cdot f^n\),它們會壓縮並在下一個層級中形成一個大小為 \(\ge s_{f} \cdot f^{n+1}\) 的新 SSTable。
-
這些方案會忽略覆寫和刪除,但如果已知覆寫/刪除的預期比例,則可以調整演算法。目前的 UCS 實作會進行此調整,但目前不會公開調整。
層級數
使用最大資料集大小 \(D\),可以如下計算層級數
此計算基於以下假設:當所有層級都滿時,會達到最大資料集大小 \(D\),而最大層級數與 \(f\) 的對數成反比。
因此,當我們試圖控制資料庫上壓縮的開銷時,我們有策略的選擇空間,範圍從
-
分層壓縮(\(t=2\)),\(f\) 較高
-
層級數較低
-
讀取效率較高
-
寫入成本較高
-
隨著 \(f\) 增加,行為更接近已排序陣列
-
-
壓縮,其中 \(t = f = 2\),分層與分層相同,而我們有一個讀取和寫入成本以對數方式增加的中間地帶;
-
分層壓縮(\(t=f\)),\(f\) 較高
-
SSTable 數量非常多
-
讀取效率較低
-
寫入成本較低
-
隨著 \(f\) 增加,會更接近未排序的記錄
-
這可以輕鬆地概括為不同的扇出係數,方法是用所有較低層級的扇出係數的乘積取代指數運算
| 層級 | 最小 SSTable 大小 | 最大 SSTable 大小 |
|---|---|---|
0 |
0 |
\(s_{f} \cdot f_0\) |
1 |
\(s_{f} \cdot f_0\) |
\(s_{f} \cdot f_0 \cdot f_1\) |
2 |
\(s_{f} \cdot f_0 \cdot f_1\) |
\(s_{f} \cdot f_0 \cdot f_1 \cdot f_2\) |
… |
… |
… |
n |
\(s_{f} \cdot \prod_{i < n} f_i\) |
\(s_{f} \cdot \prod_{i\le n} f_i\) |
基於密度的分層
如果我們用密度度量取代前述討論中的大小 \(s\)
其中 \(v\) 是 SSTable 涵蓋的令牌空間的分數,所有公式和結論仍然有效。但是,使用密度,現在可以在任意點分割輸出。如果壓縮並分割多個 SSTable,形成的新 SSTable 會比原始 SSTable 更密集。例如,使用比例參數 T4,四個輸入 SSTable 各跨越令牌空間的 1/10,在壓縮和分割後,將形成四個新的 SSTable,每個跨越令牌空間的 1/40。
這些新的 SSTable 大小相同,但更密集,因此會移至下一個較高層級,因為較高的密度值超過了原始壓縮層級的最大密度。如果我們可以確保分割點是固定的(見下文),這個程序將對每個分片(令牌範圍)重複執行,同時執行獨立的壓縮。
|
計算 \(v\) 時,考慮本地擁有的令牌份額非常重要。因為 vnodes 表示節點的本地令牌擁有權不是連續的,所以第一個和最後一個令牌之間的差異不足以計算令牌份額;因此,任何非本地擁有的範圍都必須排除在外。 |
使用密度度量讓我們能夠透過分片控制 SSTable 的大小,以及並行執行壓縮。使用大小分層壓縮,我們可以透過根據資料目錄,在固定數量的壓縮分片中預先分割資料,來實現平行化。但是,該方法需要預先確定分片數,並且對於所有層級的階層都相等,而且 SSTable 可能太小或太大。大型 SSTable 會使串流和修復複雜化,並增加壓縮作業的持續時間,將資源固定在長時間執行的作業上,並使過多 SSTable 累積在較低層級的階層上。
基於密度的分層壓縮允許更多樣化的分割選項。例如,SSTable 的大小可以保持接近所選的目標,允許 UCS 處理 STCS(SSTable 大小隨著每個層級而增加)和 LCS(令牌份額隨著每個層級而減少)的分層。
分片
基本分片方案
此分片機制與壓縮規格無關。有許多拆分 SSTable 的選擇
-
當達到特定輸出大小(例如 LCS)時拆分,形成非重疊的 SSTable 執行,而非個別 SSTable
-
在預定義的邊界點將令牌空間拆分成分片
-
在預定義的邊界拆分,但僅在達到特定最小大小時
僅按大小拆分會產生個別 SSTable,其起始位置會有所不同。若要壓縮以這種方式拆分的 SSTable,您必須選擇按順序壓縮某個層級的整個令牌範圍,或壓縮並複製某些資料多次,因為 SSTable 重疊。如果使用預定義的邊界點,某些令牌範圍可能會較稀疏,輸入較少,並會使結果 SSTable 的密度產生偏差。如果發生這種情況,可能需要進一步拆分。在混合選項中,密度偏差發生的頻率較低,但仍可能發生。
若要避免這些問題並允許壓縮層級中的所有層級同時壓縮,UCS 會為每個壓縮預定義邊界點,並始終在這些點拆分 SSTable。邊界點的數量會根據輸入 SSTable 的密度和結果 SSTable 的估計密度來決定。隨著密度變大,邊界點的數量也會增加,使個別 SSTable 的大小接近預定義的目標。使用指定基本計數的 2 的倍數,即在中間拆分分片,可確保適用於給定輸出密度的任何邊界點也適用於所有較高的密度。
可以設定兩個分片參數
-
基本分片計數 \(b\)
-
目標 SSTable 大小 \(s_{t}\)
在每個壓縮開始時,請回想輸出 \(d\) 的密度會根據 SSTable 的輸入大小 \(s\) 和令牌範圍 \(v\) 來估計
其中 \(v\) 是輸入 SSTable 涵蓋的令牌範圍的比例,值介於 0 到 1 之間。\(v = 1\) 表示整個令牌範圍都包含在輸入 SSTable 中,而 \(v = 0\) 表示輸入 SSTable 沒有涵蓋任何令牌範圍。
當 memtable 初次沖刷到 L0 時,\(v = 1\),因為整個令牌範圍都包含在 memtable 中。在後續壓縮中,令牌範圍 \(v\) 是被壓縮的 SSTable 涵蓋的令牌範圍的比例。
有了輸出的計算密度,加上 \(b\) 和 \(s_{t}\) 的值,就可以計算將令牌空間拆分成的分片數 \(S\)
其中 \(\lfloor x \rceil\) 代表 \(x\) 四捨五入到最接近的整數,也就是 \(\lfloor x + 0.5 \rfloor\)。因此,在第二種情況下,密度會除以目標大小,並四捨五入到 \(b\) 的次方倍數。如果結果小於 1,分片數目會是基礎分片數,因為記憶表會分割成 \({2 \cdot b}\),或 \(b\) 個 L0 分片。
不過,影響我們是否在 \(b\) 個分片或更多分片之間切換的因素不只有令牌範圍(條件大於或等於 1)。如果記憶表非常大,一次可以快取數個 GB,\(d\) 可能比 \(s_{t}\) 大一個數量級,並導致 SSTable 甚至在 L0 上分割成多個分片。相反地,如果記憶表很小,\(d\) 在 L0 以上的層級上可能仍然小於 \(s_{t}\),其中條件小於 1,因此會有 stem[b] 個分片。
\(S - 1\) 個邊界會產生,將本機令牌空間平均分割成 \(S\) 個分片。分割本機令牌空間會將這些邊界上的壓縮結果分割,為每個分片形成一個獨立的 SSTable。產生的 SSTable 大小會介於 \(s_{t}/\sqrt 2\) 和 \(s_{t} \cdot \sqrt 2\) 之間。
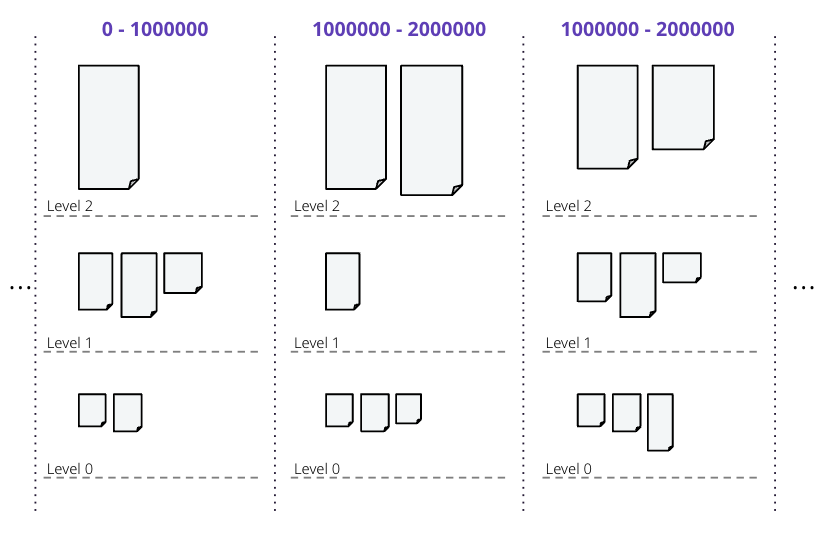
例如,我們使用 \(s_{t} = 100MiB\) 的目標 SSTable 大小和 \(b = 4\) 個基礎分片。如果快取一個 \(s_{f} = 200 MiB\) 的輸入記憶表,計算分片數目的條件為
這個計算結果為 \(0.5 < 1\),因為在初始快取時 \(v = 1\) 的值。由於結果小於 1,因此使用基礎分片數,並且記憶表會分割成四個 L0 分片,每個分片約為 50MiB。每個分片跨越令牌空間的 1/4。
為了繼續這個範例,在壓縮的下一層級中,對於四個分片中的只有一個,我們壓縮這六個 50 MiB 的 SSTable。輸出的估計密度會是
使用 1/4 作為輸入 SSTable 涵蓋的令牌範圍的 \(v\) 值。
分割條件會是
因此,分片數會計算為
或 \(2^{\log_2 3}\),取整為 \(2^2 \cdot 4\) 個分片,用於整個本機令牌空間,且壓縮涵蓋令牌空間的 1/4。假設沒有覆寫或刪除,產生的 SSTable 大小會是 75 MiB,令牌共享 1/16,密度 1200 MiB。
完整分片方案
這個分片方案可以輕易擴充。目前已實作兩個擴充,SSTable 成長和最小 SSTable 大小。
首先,讓我們檢視預期資料集大小會非常大的情況。為了避免預先指定一個夠大的目標大小,以避免每個 SSTable 負擔過重,已實作一個 SSTtable 成長 參數。這個參數會決定密度成長的哪一部分應該指定給增加的 SSTable 大小,減少分片數的成長,因此減少非重疊的 SSTable。
第二個擴充是具有固定分片數的操作模式,會在達到最小大小時有條件地分割。定義一個 最小 SSTable 大小,只要分割會產生小於提供的最小值的 SSTable,就可以減少基本分片數。
有四個使用者定義的分片參數
-
基本分片計數 \(b\)
-
目標 SSTable 大小 \(s_{t}\)
-
最小 SSTable 大小 \(s_{m}\)
-
SSTable 成長元件 \(\lambda\)
給定密度 \(d\) 的分片數 \(S\) 接著會計算為
這些參數的一些有用組合
-
上述基本方案使用 SSTable 成長 \(\lambda=0\),和最小 SSTable 大小 \(s_{m}=0\)。下方的圖表說明了基本分片數 \(b=4\) 和目標 SSTable 大小 \(s_{t} = 1\, \mathrm{GB}\) 的行為

-
使用 \(\lambda = 0.5\) 會均勻地增加分片數和 SSTable 大小。當密度增加四倍時,該密度頻段的分片數和預期 SSTable 大小都會加倍。下方的範例使用 \(b=8\), \(s_{t} = 1\, \mathrm{GB}\),並套用一個最小大小 \(m = 100\, \mathrm{MB}\)

-
類似地,\(\lambda = 1/3\) 使得 SSTable 的成長為密度成長的立方根,也就是說,SSTable 的大小會隨著分片計數成長的平方根而成長。下方的圖表使用 \(b=1\) 和 \(s_{t} = 1\, \mathrm{GB}\)(注意:當 \(b=1\) 時,最小大小沒有影響)

-
1 的成長組件會建構一個層級,在每個層級中恰好有 \(b\) 個分片。結合最小 SSTable 大小,操作模式會使用預先指定的數量分片,但僅在達到最小大小後才會分割。下方為 \(b=10\) 和 \(s_{m} = 100\, \mathrm{MB}\) 的說明(注意:當 \(\lambda=1\) 時,目標 SSTable 大小無關緊要)

選擇要壓縮的 SSTable
密度調整會根據壓縮設定的扇出因子,將 SSTable 分離到不同層級。然而,與大小調整(SSTable 預期會涵蓋完整的令牌空間)不同,層級上的 SSTable 數量無法用作觸發器,因為 SSTable 可能沒有重疊。在這種情況下,讀取查詢的效率較低。為了解決這個問題,請執行分片,在層級上同時執行多個壓縮,並減少個別壓縮操作的大小。未重疊的部分必須分為不同的區塊,而區塊中重疊的 SSTable 數量會決定要執行什麼動作。區塊是將會一起壓縮的 SSTable 的選定集合。
首先,建立一個符合下列需求的最小重疊集合清單
-
兩個沒有重疊的 SSTable 絕不會放在同一個集合中
-
如果兩個 SSTable 有重疊,清單中會有一個集合包含這兩個 SSTable
-
SSTable 會按順序放置在清單中
第二個條件也可以改寫成說,對於令牌範圍中的任何一點,清單中有一個集合包含其範圍涵蓋該點的所有 SSTable。換句話說,重疊集合給我們需要諮詢以讀取任何金鑰的最大 SSTable 數量,即我們的觸發器 \(t\) 旨在控制的讀取放大。我們不會計算或儲存重疊集合涵蓋的確切跨度,只會計算參與的 SSTable。這些集合可以在 \(O(n\log n)\) 時間內取得。
例如,如果 SSTable A、B、C 和 D 分別涵蓋令牌 0-3、2-7、6-9 和 1-8,我們會計算重疊集合清單,即 ABD 和 BCD。A 和 C 沒有重疊,因此它們必須在不同的集合中。A、B 和 D 在令牌 2 處重疊,因此它們必須至少存在於一個集合中,B、C 和 D 在 7 處也一樣。只有 A 和 D 在 1 處重疊,但集合 ABD 已經包含這個組合。
這些重疊集合足以決定是否應該執行壓縮,當且僅當集合中的元素數量至少與 \(s_{t}\) 一樣大。但是,我們可能需要在壓縮中包含比這個集合更多的 SSTable。
我們的分片架構可能會最終為同一層級的不同大小分片建構 SSTable。一個明確的範例是分層壓縮的情況。在這種情況下,SSTable 以某種密度進入,在第一次壓縮後,產生的 SSTable 比初始密度大 2 倍,導致 SSTable 在令牌範圍的中間一分為二。當另一個 SSTable 進入同一層級時,我們將在兩個較舊的 SSTable 和新的 SSTable 之間有不同的重疊集合。為了效率,接下來觸發的壓縮需要選取兩個重疊集合。
為了處理部分重疊的情況,重疊集合將與所有共享某些 SSTable 的鄰近集合遞移延伸。因此,建構的所有 SSTable 集合都有一些重疊 SSTable 鏈,將其連接到初始集合。這個延伸集合形成壓縮區塊。
|
除了 |
在正常運作中,我們會壓縮壓縮分段中的所有 SSTable。如果壓縮非常晚,我們可能會對我們壓縮的重疊來源數量套用一個限制。在這種情況下,我們會使用最舊 SSTable 的集合,這些 SSTable 最多會在任何包含的重疊集中選擇限制數量,確保如果一個 SSTable 包含在這個壓縮中,所有較舊的 SSTable 也會包含在內,以維持時間順序。
選擇要執行的壓縮
壓縮策略旨在最小化查詢的讀取放大,而讀取放大是由重疊在任何給定金鑰上的 SSTable 數量定義的。在壓縮較晚的情況下,為了達到最高的效率,會選擇重疊程度在可能的選擇中最高的壓縮分段。如果有多個選擇,請在每個層級中均勻隨機選擇一個。在層級之間,優先選擇最低的層級,因為預期這將涵蓋相同工作量的令牌空間的較大部份。
在持續負載下,此機制可防止某些層級上累積 SSTable,而這有時會發生在舊策略中。使用舊策略時,所有資源都可能被 L0 消耗,而 SSTable 則累積在 L1。使用 UCS 時,會達成一個穩態,其中壓縮始終使用比指定的閾值和扇出因子更多的 SSTable,並且基於它們能夠為負載維持的最低重疊來維持一個分層結構。
與 STCS 和 LCS 的差異
請注意,分層 UCS 和舊版 STCS 之間,以及分層 UCS 和舊版 LCS 之間存在一些差異。
分層 UCS 與 STCS
STCS 與 UCS 非常相似。但是,STCS 是透過尋找大小相似的 SSTable 來定義分段/層級,而不是使用預先定義的尺寸分段。因此,STCS 最終可能會有一些奇怪的分段選擇,跨越大小差異極大的 SSTable;UCS 的選擇更穩定且可預測。
當 STCS 在某個儲存區中發現至少有 min_threshold 個 SSTable 時,就會觸發壓縮,並一次壓縮該儲存區中介於 min_threshold 和 max_threshold 個 SSTable。min_threshold 等於 UCS 的 \(t = f = w + 2\)。UCS 會捨棄上限,因為即使 SSTable 數量非常多,其壓縮仍然很有效率。
UCS 使用密度測量來分割結果,以維持 SSTable 的大小和壓縮時間在低水準。在一個層級中,UCS 在決定是否達到閾值時,只會考慮重疊的 SSTable,並且會獨立壓縮沒有重疊的 SSTable 組。
如果在一個儲存區中有多個選擇可以挑選 SSTable,STCS 會依大小將它們分組,而 UCS 則會依時間戳記將它們分組。因此,STCS 容易遺失時間順序,這會讓整個資料表的到期時間降低效率。UCS 能有效追蹤時間順序和整個資料表的到期時間。由於 UCS 可以套用整個資料表的到期時間,因此此功能對於有生存時間限制的時間序列資料也很有用。
UCS 分層與 LCS
與 UCS 相比,LCS 的行為似乎非常不同。然而,這兩種策略實際上非常相似。
LCS 使用每個層級多個 SSTable 來形成一個由非重疊、固定大小的小 SSTable 排序執行。因此,隨著層級增加,實際的 SSTable 數量會增加(以 fanout_size 為因子),而不是大小。藉此,LCS 減少了空間放大,並確保更短的壓縮時間。當一個層級上執行項目的總大小高於預期時,它會選擇一些 SSTable 與來自下一個層級階層的重疊項目一起壓縮。最後,下一個層級的大小會超過其大小限制,並觸發更高層級的操作。
在 UCS 中,隨著層級增加,SSTable 的密度會以扇出因子 \(f\) 增加。當第二個重疊 SSTable 出現在分片層級上時,就會觸發壓縮。UCS 會壓縮該層級上的重疊儲存區,而結果通常也會出現在該層級上。但最後,資料會達到足夠的大小,可以進入下一個層級。假設資料分佈均勻,UCS 和 LCS 的行為會很類似,壓縮會在相同時間範圍內觸發。
這兩種方法最後會產生非常相似的效果。UCS 的額外好處是壓縮不會影響其他層級。在 LCS 中,L0 到 L1 的壓縮可能會阻止任何同時發生的 L1 到 L2 的壓縮,這是一個不幸的情況。在 UCS 中,SSTable 的結構讓它們可以輕鬆切換到分層 UCS 或使用不同的參數設定進行變更。
由於 LCS SSTable 僅基於大小,因此分割位置會有所不同,當 LCS 選擇在下一層級壓縮 SSTable 時,會包含一些僅部分重疊的 SSTable。因此,SSTable 的壓縮頻率可能比實際需要更頻繁。
UCS 透過在特定令牌邊界上分片來處理空間擴增的問題。LCS 根據固定大小分割 SSTable,邊界通常落在下一層級的 SSTable 內部,因此會比實際需要更頻繁地啟動壓縮。因此,UCS 有助於嚴格控制寫入擴增。這些邊界保證我們可以有效地選擇與較低密度 SSTable 範圍完全匹配的較高密度 SSTable。
UCS 選項
| 子屬性 | 說明 |
|---|---|
enabled |
啟用背景壓縮。 預設值:true |
only_purge_repaired_tombstone |
啟用此屬性可防止資料在未於 預設值:false |
scaling_parameters |
每個層級縮放參數的清單,指定為 \(L_{f}\)、\(T_{f}\)、\(N\),或直接指定 \(w\) 的整數值。如果層級數多於此清單的長度,則最後一個值會用於所有較高層級。通常這只會是一個參數,指定階層中所有層級的行為。 指定為 \(L_{f}\) 的分層壓縮適用於讀取密集的工作負載,特別是在布隆過濾器無效時(例如,使用廣泛分割區);較高的分層扇出係數會改善讀取擴增(以及延遲,以及讀取密集工作負載的處理量),但會增加寫入成本。舊版 LCS 等同於 L10。 指定為 \(T_{f}\) 的分層壓縮適用於寫入密集的工作負載,或可以利用布隆過濾器或時間順序的工作負載;較高的分層扇出係數會改善寫入成本(以及處理量),但會讓讀取變得更困難。 \(N\) 是具有分層(每個層級執行一次 SSTable)和分層(一次壓縮會提升到下一層級)的功能,以及扇出係數為 2 的中間值。此值也可以指定為 T2 或 L2。 預設值:T4(閾值為 4 的 STCS) |
目標 SSTable 大小 |
目標 SSTable 大小 \(s_{t}\),指定為以位元組為單位的使用者友善大小,例如 MiB。此策略會將資料分割成分片,目標是產生大小介於 \(s_{t}/\sqrt{2}\) 和 \(s_{t} \cdot \sqrt{2}\) 之間的 SSTable。較小的 SSTable 可改善串流和修復,並縮短壓縮時間。另一方面,磁碟上的每個 SSTable 都有不小的記憶體使用量,也會影響垃圾回收時間。如果系統中 SSTable 數量的記憶體壓力過高,請增加此值。 預設值:1 GiB |
min_sstable_size |
最小 SSTable 大小,適用於基礎分片數目會導致 SSTable 被認為過小的情況。如果設定,策略會將空間分割成少於基礎數目分片的數量,以使估計的 SSTable 大小至少與此值一樣大。值 0 會停用此功能。 預設值:100 MiB |
base_shard_count |
密度最小的層級所使用的最小分片數目 \(b\)。這會提供最低層級的最小壓縮並行性。較小的數字會導致較大的 L0 SSTable,但可能會限制整體最大寫入處理量(因為每筆資料都必須經過 L0)。 預設值:4(系統表格為 1,或定義多個資料位置時) |
sstable_growth |
SSTable 成長元件 \(\lambda\),作為分片指數計算的因子套用。這是一個介於 0 到 1 之間的數字,用來控制密度成長的哪一部分應套用於個別 SSTable 大小,以及哪一部分應增加分片數目。使用值 1 會將分片數目固定為基礎值。使用 0.5 會讓分片數目和 SSTable 大小隨著密度成長的平方根而成長。這有助於減少為非常大的資料集建立的 SSTable 數目。例如,沒有成長修正,大小目標為 1 GiB 的 10 TiB 資料集會產生超過 10K 的 SSTable。這麼多 SSTable 可能會造成過多負擔,包括每個 SSTable 結構所使用的堆上記憶體,以及壓縮期間相交 SSTable 的查詢時間和追蹤重疊集合。例如,基礎分片數目為 4 時,成長因子可以將潛在 SSTable 數目減少到約 160 個,大小約為 64 GiB,在記憶體負擔、個別壓縮持續時間和空間負擔方面都可管理。可以調整參數,增加值以在頂層取得較少但較大的 SSTable,並減少值以偏好較高數目的較小 SSTable。 預設值:0.333(SSTable 大小隨著分片數目成長的平方根而成長) |
expired_sstable_check_frequency_seconds |
決定多久檢查一次過期的 SSTable。 預設值:10 分鐘 |
max_sstables_to_compact |
一次操作中要壓縮的最大 SSTable 數目。較大的值可能會減少寫入放大,但可能會導致非常長的壓縮,因此在處理此類壓縮時會產生非常高的讀取放大負擔。預設值旨在控制操作長度,並在壓縮進行時防止 SSTable 累積。如果扇出因子大於最大 SSTable 數目,策略會忽略後者。 預設值:無(儘管 32 是個不錯的選擇) |
overlap_inclusion_method |
指定如何將重疊區段延伸到儲存區塊中。TRANSITIVE 可確保如果我們選擇一個 SSTable 進行壓縮,我們也會壓縮與它重疊的 SSTable。SINGLE 只執行一次此延伸(即只選擇與原始重疊 SSTable 區段重疊的 SSTable。NONE 沒有新增任何重疊的 SSTable。不建議使用 NONE,SINGLE 可能會以犧牲升級 LCS 或範圍移動時重新壓縮一些資料為代價,提供更多並行性。 預設值:TRANSITIVE |
unsafe_aggressive_sstable_expiration |
過期的 SSTable 會在不檢查其資料是否遮蔽其他 SSTable 的情況下被刪除。只有在 預設值:false |
在 cassandra.yaml 中,還有一個會影響壓縮的參數
- concurrent_compactors
-
允許同時進行的壓縮數量,不包括用於反熵修復的驗證「壓縮」。較高的值會提升壓縮效能,但可能會增加讀取和寫入延遲。